ASReview LAB, guía práctica para optimizar tus revisiones sistemáticas
ASReview es una tecnología de asistencia a las revisiones o TAR (technology-assited review) que agiliza el proceso de selección de artículos. El modelo asiste, el revisor elige.
Como modelo de aprendizaje activo, ASReview aprende sobre la marcha, con cada toma de decisión del investigador. Por ello, para empezar es bueno contar con un conjunto de artículos que cumplan con los criterios de inclusión (puede ser uno). A partir de ahí el revisor comienza a cribar y el modelo va clasificando por similitud, mostrando antes los que considera más parecidos y dejando para el final los que menos se parecen.
Guía de ASReview LAB paso a paso
1. Instalar ASReview LAB
ASReview LAB se puede instalar en local o en un servidor. La instalación local es la opción más práctica desde el punto de vista del investigador individual. La otra opción es contactar con servicios informáticos de tu institución e instalar ASReview en un servidor, lo que lo haría accesible desde cualquier dispositivo o navegador.
Cómo instalar y ejecutar ASReview LAB en Windows
- En el cuadro de búsqueda de la barra de navegación de Windows escribe: CMD. Los resultados de búsqueda te ofrecerán la opción de abrir «Símbolo de sistema». Ábrelo.
- Escribe python y pulsa ENTER.
- Si tienes Phyton (un lenguaje de programación) instalado aparecerá la versión con la que cuenta tu equipo. Si no lo tienes instalado se abrirá la última versión de Python en la Microsoft Store para que lo instales.
- Una vez instalado vuelve a abrir Símbolo del sistema y escribe: pip install asreview y pulsa ENTER. Se iniciará la instalación de ASReview LAB.
- Una vez finalizada la instalación escribe en símbolo de sistema asreview lab y pulsa ENTER, para abrir el programa. Cada vez que quieras iniciar el programa deberás hacerlo a través de Símbolo de Sistema ejecutando este comando. Si no se abriera con asreview lab, prueba escribiendo antes python -m: python -m asreview lab y pulsa ENTER.
Una vez instalado y en marcha ya podemos empezar una revisión sistemática. Podemos utilizar nuestro listado de referencias, o utilizar una de las bases de datos que ASReview ofrece pertenecientes al proyecto SYNERGY.
Antes de empezar con datos propios es interesante familiarizarse con ASReview LAB.
2. Primeros pasos: Revisión con base de datos SYNERGY (toma de contacto)
Esta es quizá la mejor manera de familiarizarse con el programa. Para empezar solo tenemos que ir a DISCOVER, en el menú que se despliega en la pantalla central de ASReview, fijándonos que estemos en la sección de REVIEWS.
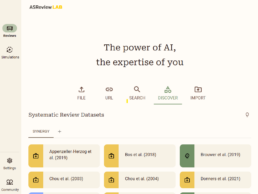
Una vez descargada se abrirá el panel desde el que podremos llevar a cabo la selección de estudios, con la ventaja de que sabremos de antemano cuántos relevantes hay, y que todos los artículos ya están etiquetados como relevantes o irrelevantes, por lo que podemos hacer pruebas cómodamente.
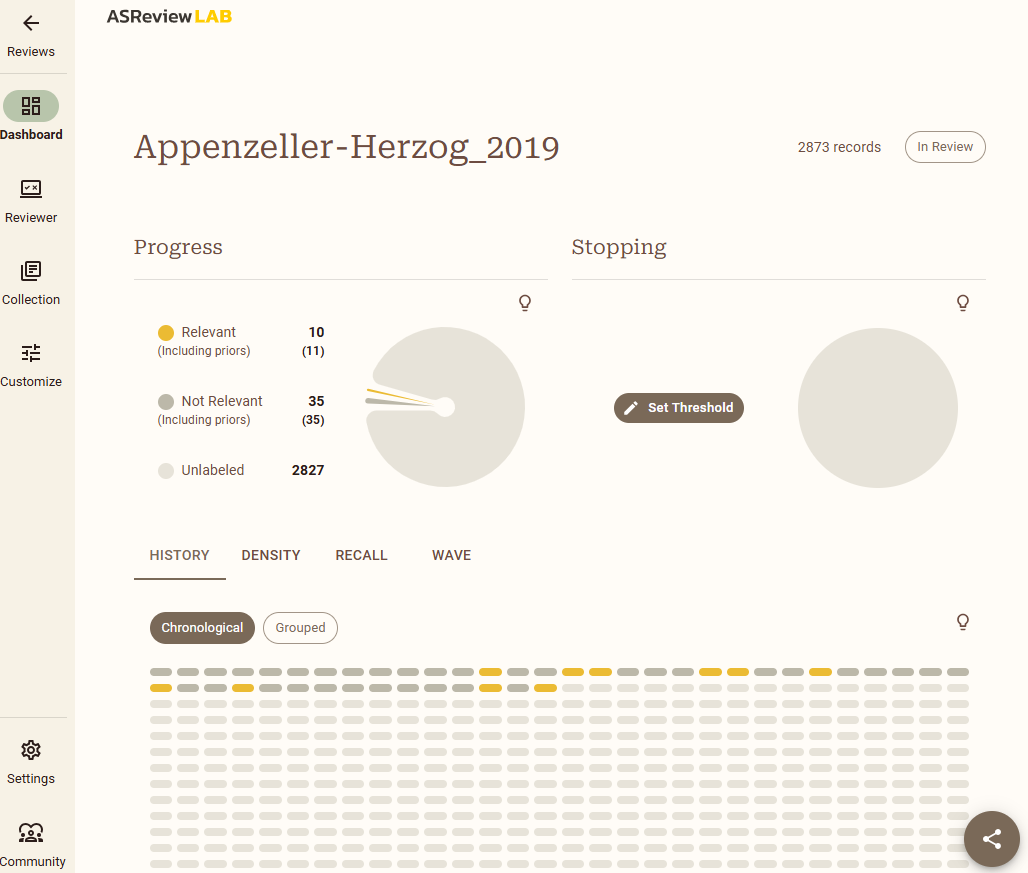
Una vez descargamos una base de datos y entramos en el proyecto, el panel de gestión de ASReview LAB es bastante intuitivo:
-
- Dashboard: donde se ve la evolución de la revisión de forma gráfica.
- Reviewer: aquí van apareciendo los artículos que hay que ir marcando como incluidos o excluidos manualmente. El aprendizaje es activo, por lo que el investigador tiene que empezar etiquetando los artículos que va sugiriendo el algoritmo aplicando los criterios que haya previamente fijado.
Como veis la estrategia es la misma que a la vieja usanza: leer título, leer resumen, y tomar la decisión. Según vamos avanzando el algoritmo irá aprendiendo y la cantidad de artículos relevantes que nos muestre será mayor, dejando para el final los no relevantes, llegando un punto en el que solo queden no relevantes (se supone), y que la probabilidad de que se haya escapado uno relevante sea muy baja. Y como la tarea de revisión siempre es algo «tediosa» , en ASReview lo han tenido en cuenta y han dejado a su mascota ELAS asomada en la esquina superior derecha por si el usuario quiere tomarse un descanso y refrescarse cognitivamente.
-
- Collection: desglose detallado de los artículos donde se podrá modificar la toma de decisión si en la revisión por pares hay desacuerdo y por consenso se modifica la clasificación.
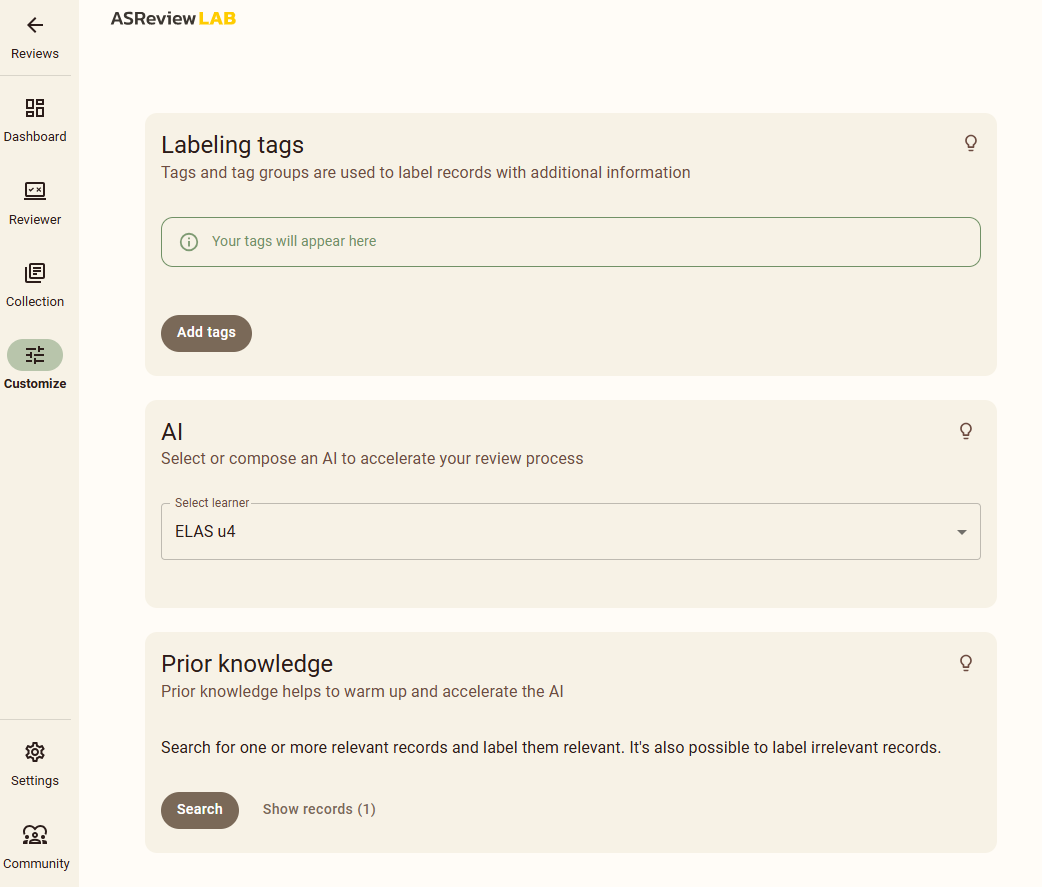
- Customize: permite elegir el modelo IA que queremos usar, y etiquetar el conocimiento previo o referencias semillas de artículos que se ajustan a nuestros criterios de inclusión, y el grupo de artículos semilla que no. Al trabajar con una base de datos ya etiquetada podemos ir a SYNERGY, abrir el archivo csv de la base de datos que estemos utilizando, y buscar con el doi de algunos de los artículos que ya están marcadas como relevantes e irrelevantes, para definir el prior knowledge. Copiamos el título y lo buscamos a través de prior knowlede.
En Settings(rueda dentada abajo a la izquierda) podemos modificar el entorno de trabajo (claro, oscuro), mostrar la información del modelo sobre los artículos en las pestañas REVIEWER y COLLECTION
Después de trastear un rato y familiarizados con el entorno, estamos preparados para empezar con una revisión propia.

Cómo hacer una revisión sistemática con ASReview LAB
1. Carga de referencias
Antes de cargar las referencias bibliográficas de tu revisión sistemática, o de alcance, deberás preparar la base de datos. Lo primero es unificar los archivos que hayas bajado de las bases de datos electrónicas (p. ej., PubMed, Scopus, PsycINFO) y eliminar los duplicados.
A continuación, hay que comprobar que la base de datos contenga como mínimo el título y el abstract, siendo recomendable incluir también el DOI, ya que facilitará la consulta del artículo en caso de necesidad.
La base de datos puede estar en .csv, .tab, .tsv, .xlsx, o .ris. Si trabajas con un gestor de referencias como Mendeley o Zotero y tienes todas tus referencias en una carpeta (ej. SR_pre_cribado), puedes descargar todo en .ris e importar ese archivo en ASReview cómodamente al terminar la revisión.
2.Selección del modelo
Una vez cargadas las referencias y dentro del panel de gestión de la revisión, tenemos que elegir el modelo IA con el que queremos trabajar. Para ello hay que abrir la pestaña CUSTOMIZE del menú lateral izquierdo.
ASReview cuenta con 3 modelos: ELAS Ultra, ELAS Multilingual y ELAS Heavy.
- ELAS Ultra: es el más ampliamente utilizado. Es rápido, eficiente y versátil.
- ELAS Multilingual: como su nombre permite intuir, es para proyectos que revisen literatura en varios idiomas (soporta más de 100 idiomas), y donde los investigadores busquen un mayor control. Eso sí, requiere instalar la extensión Dory y contar con un equipo que soporte la demanda de procesamiento que requiere (16GB de RAM, un procesador multinúcleo con alta velocidad de reloj, y una GPU moderna).
- ELAS Heavy: está diseñado para tareas pesada como aquellas que requieren comprensión semántica avanzada de textos, donde se busca entender en contexto semántico. Al igual que en ELAS Multilingual necesitamos instalar Dory y un ordenador moderno y potente.
Además de estos tres modelos ASReview ofrece la posibilidad de personalizar el modelo ELAS según las necesidades del estudio.
3. Entrenamiento inicial del modelo (prior knowledge)
En la misma pestaña, encontramos la opción para declarar cuáles son los artículos con los que vamos a entrenar al modelo: prior knowledge.
Para el entrenamiento inicial del modelo de aprendizaje activo debes tener un conjunto de artículos previamente seleccionados (artículos semilla) en tu base de datos como relevantes e irrelevantes.
Según ASReview puede ser uno de cada, aunque también señalan que un conocimiento previo preciso (de calidad) mejora el desempeño del algoritmo, por lo que incrementar el número de artículos semilla puede ser una buena estrategia, aunque no hay un valor fijo definido.
En prior knowledge buscamos los artículos por su título, y los marcamos como relevantes o irrelevantes.
4. Determinación del punto de detención (stopping rule)
El revisor continuará con el cribado hasta alcanzar un punto de detención o stopping rule, que puede definirse en el programa en base a dos criterios heurísticos:
- Un número fijado de estudios no relevantes seguidos.
- Un porcentaje X de la muestra.
Estos criterios son útiles en la práctica, pero por sí solos no permiten saber con certeza si se ha alcanzado el nivel de recuperación deseado.
En Callaghan et al. (2024) señalan que lo criterios de parada deben estar ligados a un objetivo explícito de recall (nivel de recuperación de artículos objetivo) y a estimaciones de confianza, y no depender de parámetros heurísticos que no informan sobre la probabilidad de haber alcanzado un nivel de recall objetivo.
Como criterio estadístico de parada para el aprendizaje activo Callaghan y Müller-Hansen (2020) aplicaron la distribución hipergeométrica, la cual requiere iniciar la revisión e ir calculando según se va avanzando si se ha alcanzado el recall objetivo previamente definido, por ejemplo un 95%.
Para saber si se ha alcanzado el punto de parada sobre la marcha, Callaghan and Müller-Hansen han implementado la aplicación BUSCAR, la cual utiliza el número de artículos consecutivos irrelevantes y aplica la distribución hipergeométrica para calcular la probabilidad de no encontrar ningún registro relevante en la muestra de irrelevantes que se indique, ofreciendo un valor p que cuantifica cuánta evidencia aportan los datos observados contra la hipótesis de que no se haya alcanzado el recall deseado. No calcula el punto de parada, evalúa si los datos observados ya permiten justificarlo.
Carga de trabajo vs. garantía de recuperación de artículos
Si revisamos el artículo de Callaghan y Müller-Hansen (2020) observamos que el uso de TAR no supondrá un excesivo ahorro de tiempo sobre todo si la muestra de artículos relevantes esperable no es grande, algo habitual si tenemos en cuenta la prevalencia de artículos relevantes que recoge el proyecto SYNERGY (De Bruin et al., 2023) de un 1,67%.
Por ejemplo, si introducimos en BUSCAR la muestra del artículo de Appenzeller-Herzog (2019) de 2873 artículos, y definimos: un recall objetivo del 95%, indicamos que hemos encontrado 26 artículos relevantes (que son todos los que hay en la muestra), y señalamos que llevamos 250 artículos no relevantes seguidos, para alcanzar un valor p=0,5 se tienen que haber revisado 2268 artículos, lo que supone un ahorro del 21%, si queremos llegar a p=0.05 tendríamos que clasificar casi todos los artículos (2801), lo que solo supondría un ahorro del 2,5%.
Si seguimos probando con BUSCAR e incrementamos a 500 artículos los no relevantes consecutivos, alcanzaríamos un valor p=0.5 al llevar 1667 artículos revisados, lo que supondría un ahorro del 41% del trabajo. Es decir, cuanto más eficiente sea el modelo, antes encontraremos el punto de detención. Para llegar a p=0.05 tendríamos que subir a 2728 artículos revisados, por lo que el ahorro de trabajo sería del 5%.
Ahora solo queda decidir si nos conformamos con que sea bastante improbable que se haya incumplido el objetivo de recall fijado (p=0.5), o queremos rechazar con mucha confianza la hipótesis nula de que el recall alcanzado es inferior al recall objetivo (p=0.05).
Eso sí, si nos conformamos con p=0.5 deberemos justificar los motivos, ya que este umbral no equivale a una garantía estadística fuerte, sino a un compromiso pragmático entre eficiencia y control del riesgo.
¿Vale la pena usar ASReview LAB si el ahorro de trabajo es bajo? Desde un punto de vista práctico sí, ya que agiliza la aparición de relevantes, y si el modelo funciona bien, podremos parar antes de terminar de revisar todo el corpus.
5. Proceso iterativo de selección
Una vez dado de alta el prior knowledge, seleccionado el modelo y determinado el punto de detención, tenemos dos opciones:
- Revisamos solos, o de forma consecutiva con varios revisores (revisión múltiple).
- La revisión es por pares,: en este caso ambos revisores pueden configurar los mismos parámetros, o pueden aplicar una configuración del modelo y del previous knowledge diferente.
Independientemente de la estrategia que escojamos para maximizar la validez, para iniciar la revisión tenemos que abrir la pestaña REVIEWER, donde irán apareciendo de manera aleatoria los artículos pendientes de clasificar en función de los criterios de inclusión y exclusión fijados en el protocolo.
El modelo irá aprendiendo con cada toma de decisión, priorizando los artículos que considere relevantes y dejando a cola los que considere irrelevantes.
La ventaja de ASReviwe LAB es que en cualquier momento podemos exportar el proyecto y pasárselo a otro revisor para que continúe donde lo hemos dejado.
6. Exportación de resultados
Una vez finalizada la revisión podremos exportar el proyecto y seguir trabajando con los artículos relevantes, no sin olvidar consensuar discrepancias y calcular el índice de concordancia si hemos aplicado el doble cribado independiente.
Si documentamos bien todo el proceso no perderemos poder metodológico, lo ganaremos. ASReview LAB nos ayuda registrando cada toma de decisión para facilita la reproductibilidad, contribuyendo así a alcanzar los principios FAIR (Findable, Accessible, Interoperable, Reusable).
Estrategia que se verá enriquecida con el uso de plataformas como OSF, Zenodo, o cualquier repositorio institucional, donde podemos depositar los datos para hacerlos accesibles, y facilitar que cualquiera puede reutilizarlos y replicar nuestro estudio.
Referencias y materiales consultados:
- ASReview LAB guide — ASReview LAB 0.1.dev1+g4d5d0eda4 documentation. (2025). Readthedocs.io. https://asreview.readthedocs.io/en/latest/lab/index.html
- ASReview LAB. Introductory exercise to ASReview LAB https://asreview.github.io/asreview-academy/ASReviewLAB.html
- ASReview LAB developers. (2023). ASReview LAB: A tool for AI-assisted systematic reviews [Software v.2.2]. Zenodo. https://doi.org/10.5281/zenodo.3345592
- Asreview. (2021). How to stop screening? · asreview/asreview · Discussion #557. GitHub. https://github.com/asreview/asreview/discussions/557?utm
- ASReview LAB v0.19: RIS-file import/export functionality (2022) https://www.youtube.com/watch?v=-Rw291AE2OI
- BiblioGETAFE (2025) IA en Revisiones Sistemáticas: ¿Dónde aporta y cómo usarla bien? https://bibliogetafe.com/2025/10/22/ia-en-revisiones-sistematicas-donde-aporta-y-como-usarla-bien/
- Boetje & van de Schoot (2024) — The SAFE procedure: a practical stopping heuristic for active learning-based screening in systematic reviews and meta-analyses https://systematicreviewsjournal.biomedcentral.com/articles/10.1186/s13643-024-02502-7
- Callaghan, M., Finn Müller-Hansen, Bond, M., Hamel, C., Devane, D., Kusa, W., O’Mara-Eves, A., Spijker, R., Stevenson, M., Stansfield, C., Thomas, J., & Minx, J. C. (2024). Computer-assisted screening in systematic evidence synthesis requires robust and well-evaluated stopping criteria. Systematic Reviews, 13(1), 284–284. https://doi.org/10.1186/s13643-024-02699-7
- Callaghan, M. W., & Finn Müller-Hansen. (2020). Statistical stopping criteria for automated screening in systematic reviews. Systematic Reviews, 9(1), 273–273. https://doi.org/10.1186/s13643-020-01521-4
- De Bruin, Jonathan; Ma, Yongchao; Ferdinands, Gerbrich; Teijema, Jelle; Van de Schoot, Rens (2023) «SYNERGY – Open machine learning dataset on study selection in systematic reviews», https://doi.org/10.34894/HE6NAQ, DataverseNL, V1
SYNERGY dataset https://github.com/asreview/synergy-dataset/tree/master
- Lombaers, P., de Bruins, J. y van de Schoot, R. (2023) Reproducibility and Data storage Checklist for Active Learning-Aided Systematic Reviews. PsyArXiv https://doi.org/10.31234/osf.io/g93zf
- Tejedor, N. G. (2024). ¿Qué son Datos FAIR y cuándo hay que depositar los datos de investigación en un repositorio? | Investiga UNED. Uned.es. https://investigauned.uned.es/que-son-datos-fair-y-cuando-hay-que-depositar-los-datos-de-investigacion-en-un-repositorio/
- van de Schoot, R., de Bruin, J., Schram, R. et al. An open source machine learning framework for efficient and transparent systematic reviews. Nat Mach Intell 3, 125–133 (2021). https://doi.org/10.1038/s42256-020-00287-7
- van Haastrecht, M., Sarhan, I., Yigit Ozkan, B., Brinkhuis, M., & Spruit, M. (2021). SYMBALS: A Systematic Review Methodology Blending Active Learning and Snowballing. Frontiers in Research Metrics and Analytics, 6. https://doi.org/10.3389/frma.2021.685591
Nota metodológica sobre el uso de inteligencia artificial
En la elaboración de este artículo se ha utilizado inteligencia artificial como herramienta de apoyo para la consulta, discusión, organización y clarificación de información, así como para facilitar la redacción o supervisión preliminar de algunos contenidos.